

Process Scheduling Algorithms
Process Scheduling Algorithms are given below:
i. First Come First Serve (FCFS) Scheduling
It is a non-preemptive scheduling algorithm.
The process which arrives first gets executed first or the process which requests the CPU first gets the CPU allocated first.
First Come First Serve, is just like FIFO (First in First out) Queue data structure, where the data element which is added to the queue first, is the one who leaves the queue first.
A perfect real-life example of FCFS scheduling is buying tickets at the ticket counter.
Advantages
FCFS algorithm doesn’t include any complex logic, it just puts the process requests in a queue and executes it one by one. Hence, FCFS is pretty simple and easy to implement.
Eventually, every process will get a chance to run, so starvation doesn’t occur.
Disadvantages
There is no option for pre-emption of a process. If a process is started, then the CPU executes the process until it ends.
Because there is no pre-emption, if a process executes for a long time, the processes in the back of the queue will have to wait for a long time before they get a chance to be executed.
ii. Shortest Job First (SJF) Scheduling
It is a non-preemptive scheduling algorithm.
It is also known as the shortest job next (SJN)
It is a scheduling policy that selects the waiting process with the smallest execution time to execute next.
Advantages.
The throughput is increased because more processes can be executed in less amount of time.
Having minimum average waiting time among all scheduling algorithms.
Disadvantages:
It is practically infeasible as Operating System may not know burst time and therefore may not sort them.
Longer processes will have a more waiting time, eventually, they’ll suffer starvation.
iii. Shortest Remaining Time (SRT) Scheduling
It is a preemptive scheduling algorithm.
It is also called Preemptive shortest job first or Shortest remaining time next or Shortest remaining time first.
In this scheduling algorithm, the process with the smallest amount of time remaining until completion is selected to execute. Since the currently executing process is the one with the shortest amount of time remaining by definition, and since that time should only reduce as execution progresses, processes will always run until they complete or a new process is added that requires a smaller amount of time.
Advantage:
Short processes are handled very quickly.
The system also requires very little overhead since it only makes a decision when a process completes or a new process is added.
When a new process is added the algorithm only needs to compare the currently executing process with the new process, ignoring all other processes currently waiting to execute.
Disadvantage:
Like the shortest job first, it has the potential for process starvation.
Long processes may be held off indefinitely if short processes are continually added.
iv. Priority Scheduling
In this scheduling, Priority is assigned for each process.
The process with the highest priority is executed first and so on.
Processes with the same priority are executed in the FCFS manner.
Priority can be decided based on memory requirements, time requirements or any other resource requirement.
Advantages of Priority Scheduling:
The priority of a process can be selected based on memory requirement, time requirement or user preference.
For example, a high-end game will have better graphics, which means the process which updates the screen in a game will have higher priority so as to achieve better graphics performance.
Disadvantages:
A second scheduling algorithm is required to schedule the processes which have the same priority.
In preemptive priority scheduling, a higher priority process can execute ahead of an already executing lower priority process. If the lower priority process keeps waiting for higher-priority processes, starvation occurs.
Priority scheduling is of both types: preemptive and non-preemptive.
a. Non-Preemptive Priority Scheduling:
In the Non Preemptive Priority scheduling, The Processes are scheduled according to the priority number assigned to them.
Once the process gets scheduled, it will run till the completion.
Generally, the lower the priority number, the higher is the priority of the process.
b. Preemptive Priority Scheduling:
In Preemptive Priority Scheduling, at the time of arrival of a process in the ready queue, its priority is compared with the priority of the other processes present in the ready queue as well as with the one which is being executed by the CPU at that point of time. The One with the highest priority among all the available processes will be given the CPU next.
v. Round Robin Scheduling:
CPU is assigned to the process for a fixed amount of time.
This fixed amount of time is called time quantum or time slice.
After the time quantum expires, the running process is preempted and sent to the ready queue.
Then, the processor is assigned to the next arrived process.
It is always preemptive scheduling algorithm
Advantages
It gives the best performance in terms of average response time.
It is best suited for the time-sharing system, client-server architecture, and interactive system.
Disadvantages
It leads to starvation for processes with larger burst time as they have to repeat the cycle many times.
Its performance heavily depends on time quantum.
Priorities cannot be set for the processes.
vi. HRRN (Highest Response Ratio Next):
Highest Response Ratio Next (HRNN) is one of the most optimal scheduling algorithms.
This is a non-preemptive algorithm in which, the scheduling is done on the basis of an extra parameter called Response Ratio.
A Response Ratio is calculated for each of the available jobs and the Job with the highest response ratio is given priority over the others.
Response Ratio is calculated by the given formula,
Response Ratio = (WT+BT)/BT
Where WT → Waiting Time
BT → Service Time or Burst Time
Advantages-
It performs better than SJF Scheduling.
It not only favors shorter jobs but also limits the waiting time of longer jobs.
Disadvantages-
It cannot be implemented practically. This is because the burst time of the processes cannot be known in advance.
vii. Real-Time Scheduling
A real-time system is one in which time plays an essential role since processing should be done within the defined time limit otherwise the system will fail.
Generally, in this type of system, one or more physical devices external to the computer generate the real-time data (stimuli) and the computer must react appropriately to them within a fixed amount of time.
The algorithm that is used to schedule such a real-time system periodically is known as Real-Time Scheduling Algorithm.
E.g. the computer attached with Compact Disc Player gets the bits as they come off the drive and must start converting them into music with a very tight time interval.
If the calculation takes too long the music sounds peculiar.
Other example includes Autopilot aircraft, Robot control in automated factory, Patient monitoring factory(ICU), etc.
Real-Time scheduling algorithm includes:
a. Rate Monotonic Algorithm (RM)
This is a fixed priority algorithm and follows the philosophy that higher priority is given to tasks with the higher frequencies. Likewise, the lower priority is assigned to tasks with the lower frequencies. The scheduler at any time always chooses the highest priority task for execution. By approximating a reliable degree the execution times and the time that it takes for system handling functions, the behavior of the system can be determined apriority.
b. Earliest Deadline First Algorithm(EDF)
This algorithm takes the approach that tasks with the closest deadlines should be meted out the highest priorities. Likewise, the task with the latest deadline has the lowest priority. Due to this approach, the processor idle time is zero and so 100% utilization can be achieved.
viii. Multilevel Queue
In the multilevel queue scheduling algorithm partition the ready queue has divided into seven separate queues. Based on some priority of the process; like memory size, process priority, or process type these processes are permanently assigned to one queue.
Each queue has its own scheduling algorithm. For example, some queues are used for the foreground process and some for the background process.
The foreground queue can be scheduled by using a round-robin algorithm while the background queue is scheduled by a first come first serve algorithm.
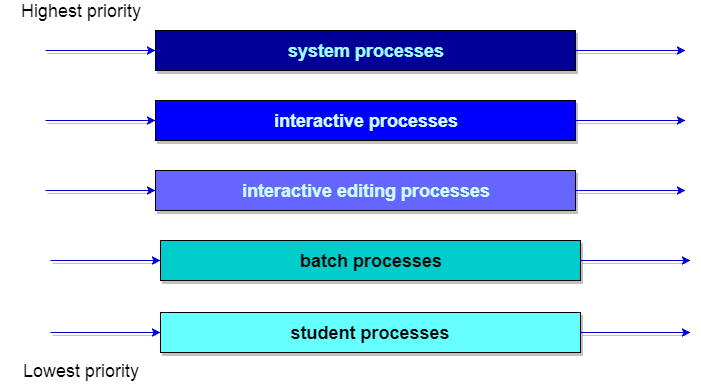
It is said that there will be scheduled between the queues which are easily implemented as fixed-priority preemptive scheduling. Let us take an example of a multilevel queue scheduling algorithm with five queues:
System process.
Interactive processes.
Interactive editing processes.
Batch processes.
Student processes.
ix. Multilevel Feedback Queue
In multilevel queue scheduling, algorithm processes are permanently stored in one queue in the system and do not move between the queue.
There is some separate queue for foreground or background processes but the processes do not move from one queue to another queue and these processes do not change their foreground or background nature, this type of arrangement has the advantage of low scheduling but it is inflexible in nature.
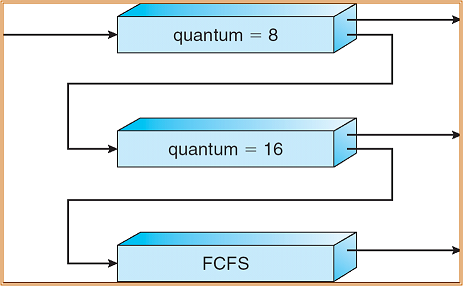
Multilevel feedback queue scheduling allows a process to move between the queue. This the process are separate with different CPU burst time.
If a process uses too much CPU time, then it will be moved to the lowest priority queue.
This idea leaves I/O bound and interactive processes in the higher priority queue.
Similarly, the process which waits too long in a lower priority queue may be moved to a higher priority queue. This form of aging prevents starvation.
The multilevel feedback queue scheduler has the following parameters:
The number of queues in the system.
The scheduling algorithm for each queue in the system.
The method used to determine when the process is upgraded to a higher-priority queue.
The method used to determine when to demote a queue to a lower – priority queue. The method used to determine which process will enter the queue and when that process needs service.
You may also like: Scheduling Techniques
Leave a Reply